I don't know. An internet alias used by me?
The domain name was available, and it's a cool combination of "hacks" and the norwegian Æ.
It's pronounced like "hacks", as in "That dude hacks everything".
Also HEX (magic and spell casting) is pretty cool because I love games and mysteries.
All together, HÆX. Seems to describe me 😅
Internationally (where the æ is not common) the domain name can be used as xn--hx-1ia.com (Internationalized domain name)
"Feedback loops" are such an incredibly useful concept. All websites, services, and such should have a "feedback" button very available.
- Clients who uses services can easily send feedback on issues or ideas for improvements
- Providers can easily aggregate information and make their services better, and/or track and continue exploring ideas from the feedback with their client
Providers should be overly open and relaxed for incoming feedback.
E. g. when chatbots forces the user to select premeditated steps and alike. The Provider must be open minded for the client, because they don't know the clients problem like they do.
This is not ment as a doomers post, I love the AI technology, but we all need to think about consequences. Here are some thoughts (might be updated over time).
This is assuming an AI could do what a human could do;
- What do we do when/if AI's start signing up emails, creating websites, sharing etc, because they need it to complete a task?
- What do we do if/when AI's start making passport, or order fake passports from the darknet?
- What could happen if an AI breaks certain ciphers and launches huge botnets at a scale and speed faster than any current tech could withstand?
- What happens if we don't solve the one human=one digital identity problem before other humans uses AI technology to launch gigantic scams?
- Scam centers are already a problem, what happens when/if (I assuming it's ongoing) they start deploying AI tech to just call everybody at the same time?
Some solutions and/or thoughts:
- Spread knowledge about security
- Spread knowledge about current technology trying to solve important problems: e.g. Cardano (blockchain digital identity, blockchain governance, accountability of information sharing/fact checking, etc..)
Other thoughts:
- What happens when humanity "solves" or figure out what consciousness is?
- If brain waves can be decoded, how will the world work? A hacker gadget might be able to scan brains and "see" their memories/thoughts
- What happens if we solve energy, like fusion? Everything is suddenly available for anyone
Oi, livet er litt av en reise, og man ser tilbake og frem og i alle kanter for å finne sin vei.
Jeg følger min egen ideologi om åpenhet og sannhet, ting er som det er 😅
Det er fint å huske at man har grunner til hvorfor ting skjer i dette universet, "live and learn" er virkelig fint å ha bak øret.
Dette innlegget får være en slags sammenfatning av hvorfor jeg har gjort som jeg har gjort i mitt liv, og tanken om at depresjon er noe vi som mennesker må få tatt tak i. Jeg har selv gått gjennom reisen fra deprimert til .. "ikke deprimert?". Jeg fant ut av det på min min måte, i mitt liv, i min situasjon, og jeg håper at andre mennesker som sliter med depresjon får medisinene de trenger og når sitt fulle potensiale.
Teknologi beveger seg veldig fort om dagene, her er litt aggregert informasjon som kanskje er nyttig, skrevet for samle mine egne tanker om situasjonen litt også.
Kunstig intelligens
The Basics
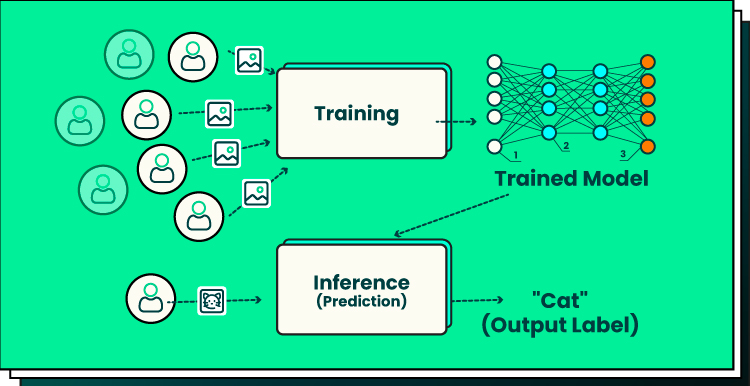
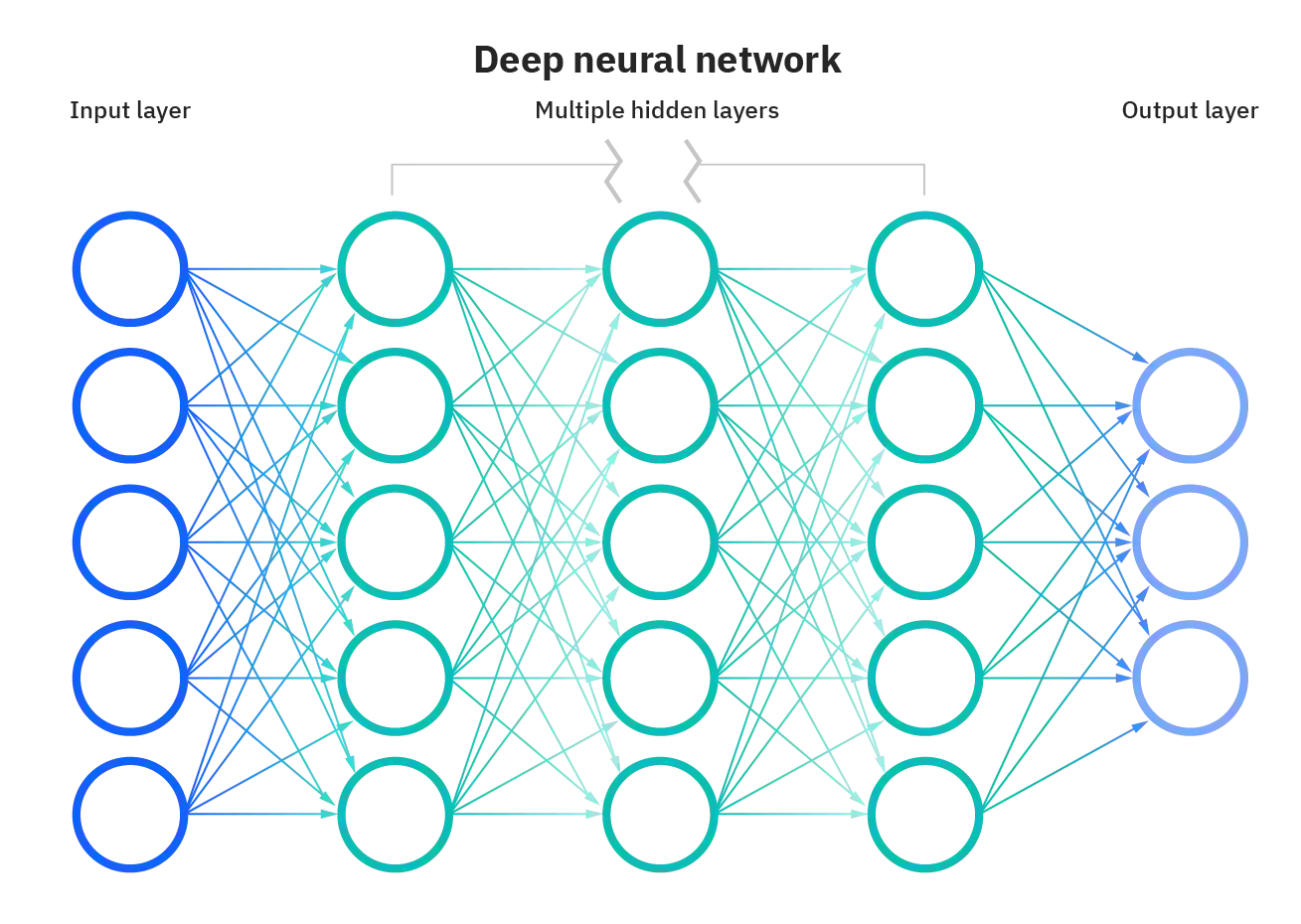
Når det snakkes om "en AI" nå til dags så snakkes det om modeller. Disse modellene kan anses som en slags hjerne, de er datafiler på titallts gigabytes. Disse modellene lages/trenes ved å bruke enorme mengder data og datakraft.
Data som brukes er typisk hentet fra internett; forsikringspriser, reddit, forumer, facebook, twitter/X, wikipedia, or annet, you name it.
Datakraften som trengs kommer typisk fra grafikkort, fordi grafikkort kan gjøre veldig mye prosessering på en gang. Her er NVIDIA og andre skjermkort-produsenter store medvirkere.
I bunn og grunn, etter hva jeg forstår, så er en modell ulike koblinger mellom data. Det er på en måte en gigantisk CSV-fil med tall som representerer hvordan informasjon er koblet sammen (vektormatriser).
En god beskrivelse fra wikipedia; "et systems evne til å korrekt tolke eksterne data, å lære av slike data, og å bruke denne kunnskapen til å oppnå spesifikke mål og oppgaver gjennom fleksibel tilpasning"
Visuell guiding



De store spillerne
Google
Fra Google Deepmind, Google sin modell i dag er PaLM 2: https://ai.google/discover/palm2/
Man kan chatte med den her: https://bard.google.com/chat
Nylig publiserte Google Gemini som er en enda smartere og bedre modell, som kan forstå multimedia på veldig interessante måter. Gemini kommer trolig til å "erstatte" PaLM2 og fungerer som Google-assistenten.
https://www.youtube.com/@Google/videos
https://deepmind.google/technologies/gemini/
Det er gratis (spørs hvordan man definerer gratis) å bruke disse tjenestene.
OpenAI / Microsoft
OpenAI ble laget av gjengen Elon Musk, Sam Altman, Ilya Sutskever, Greg Brockman. Selskapet skulle være åpent og ledende, men har blitt kjøpt opp/inn av Microsoft og de har blitt mer som en "closed sources" bedrift.
ChatGPT er et grensesnitt fra OpenAI som virkelig gjorde fart på AI-bølgen. Modellene er ChatGPT 3.5 og , ChatGPT 4. Det koster penger å bruke disse tjenestene.
https://chat.openai.com/
Grok / X / Elon Musk
Elon Musk har alltid ønsket mer åpenhet og har vært pådriver for dette, så han laget Grok, en annen modell, mye basert på data fra X, tidligere Twitter, som han ønsker skal være en åpen plattform for mennesker.
Huggingface
Huggingsface er et samlested der det deles modeller, datasett, veiledninger og annet angående AI, laget "av folket".
https://huggingface.co/
Bekymringer og sikkerhet
Utvikling av denne teknologien kan ha konsekvenser, og AI safety er et stort ønske av mange. Det virker som at Elon Musk og Ilya Sutskever har store bekymringer, men det er ikke lett å vite hva/fra hvem og hvordan fremtiden spiller ut her.
Når folk som Ilya Sutskever (en av de mest siterte forskerne noensinne), og Elon Musk (Paypal/X/Tesla/SpaceX/osv..) viser sterke bekymringer, så tror jeg at verden burde pause litt og stille spørsmål rundt utvikling. Eller i hvert fall kreve å vite hva bekymringene er. Jeg tror åpenhet er viktig for denne fremtiden, vi får se.
David Shapiro har forresten veldig mange nyttige videoer og tanker rundt dette, som jeg anbefaler å sjekke:
https://www.youtube.com/@DaveShap
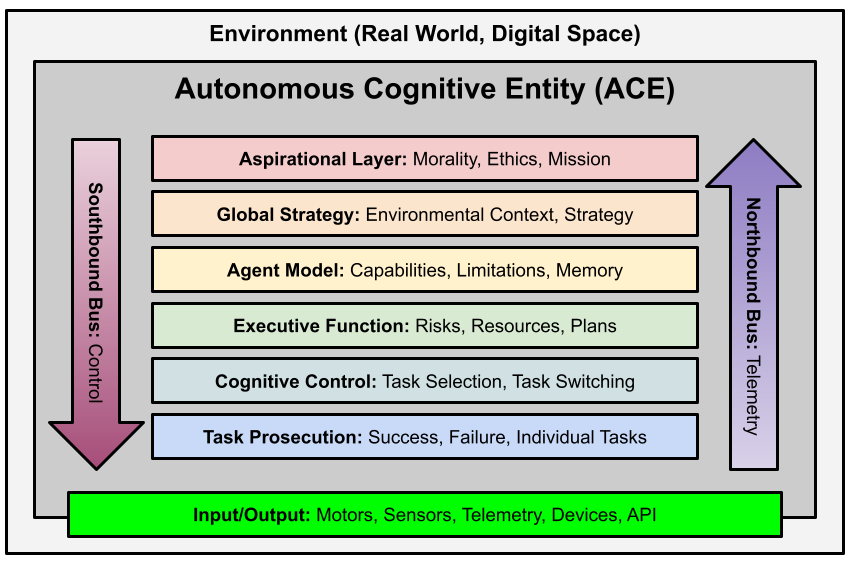
Han står også bak mange interessante rammeverk for hvordan AI burde fungere på en sikker måte, f. eks. https://github.com/daveshap/ACE_Framework